
今年度より、オンプレミスの新しいハイエンドPCを購入しました。特にグラフィックスは、現在NVIDIA社が提供する中で最高性能のGeForce RTX 4090を搭載しています。本記事では、前世代のGeForce RTX 3090と比較して、ディープラーニングの計算速度がどれくらい速くなったのか実験結果を紹介します。
PCスペック
今回購入したマシンのスペックは以下の通りです。いずれもハイエンドのものをカスタムしています。
CPU: Intel Core i9 13900KS
メモリ: 16GB PC5-38400 DDR5-SDRAM
GPU: NVIDIA GeForce RTX 4090 24GB
SSD(M2): Samsung MZ-V8P1 T0B 980 PRO 1TB
ハードディスク: 4TB SATA3
マザーボード: MSI MPG Z790 CARBON WIFI (DDR5)
電源: OWL TECH OWL-GPR1000 1000W
また、比較に用いたPCのデバイスは以下の通りです。
CPU: Intel Core i7 10700
GPU: NVIDIA GeForce RTX 3090 24 GB
Deep learningベンチマークデータセット
今回は、Deep learningで最も基本的なデータセットである、MNISTとCIFAR10を用いました。
MNIST
下図のように数字の0~9までが手書きで書かれた画像と正解ラベルから構成されます。画像サイズは28ピクセル×28ピクセルで、6万枚の学習データと1万枚のテストデータが与えられています。

CIFAR10
下図のように10クラスの動物や乗り物の画像が6000枚ずつ与えられています。画像サイズは32ピクセル×32ピクセル×3チャンネルです。

学習コード
今回はPyTorchを用いて実装しました。まず、必要なライブラリをimportします。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
続いて、Deep learningモデルを定義します。MNISTにはMLPを、CIFAR10にはCNNを用いました。
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(28*28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28*28)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3)
self.fc1 = nn.Linear(32*6*6, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(-1, 32*6*6)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
データセットを読み込みます。PyTorchなどのライブラリでは、MNISTやCIFAR10を読み込んでくれる便利な関数が定義されています。下記はMNISTを読み込んだ例です。
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
学習パラメタを設定します。今回はバッチサイズ64, エポック30としました。学習データ数はいずれも6万です。CNNを使う場合はModelのところを変更してください。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(Model.parameters(), lr=0.001)
EPOCH = 30
それでは学習していきましょう。time関数で学習時間を計測します。
start_time = time.time()
for epoch in range(EPOCH):
epoch_loss = 0
for i, data in enumerate(train_loader):
x, label = data
x, label = x.to(device), label.to(device)
optimizer.zero_grad()
y = Model(x)
loss = criterion(y, label)
loss.backward()
optimizer.step()
epoch_loss += loss
print(f'Epoch: {epoch+1}, Loss: {epoch_loss/len(train_loader):.3f}')
end_time = time.time()
total_time = end_time - start_time
print(f'Training completed in {total_time // 60:.0f}m {total_time % 60:.0f}s')
測定結果
MNIST, CIFAR10を4090, 3090 GPUで学習した際に掛かった時間は下図のようになりました。また、それぞれのCPUで測定した結果も載せています。
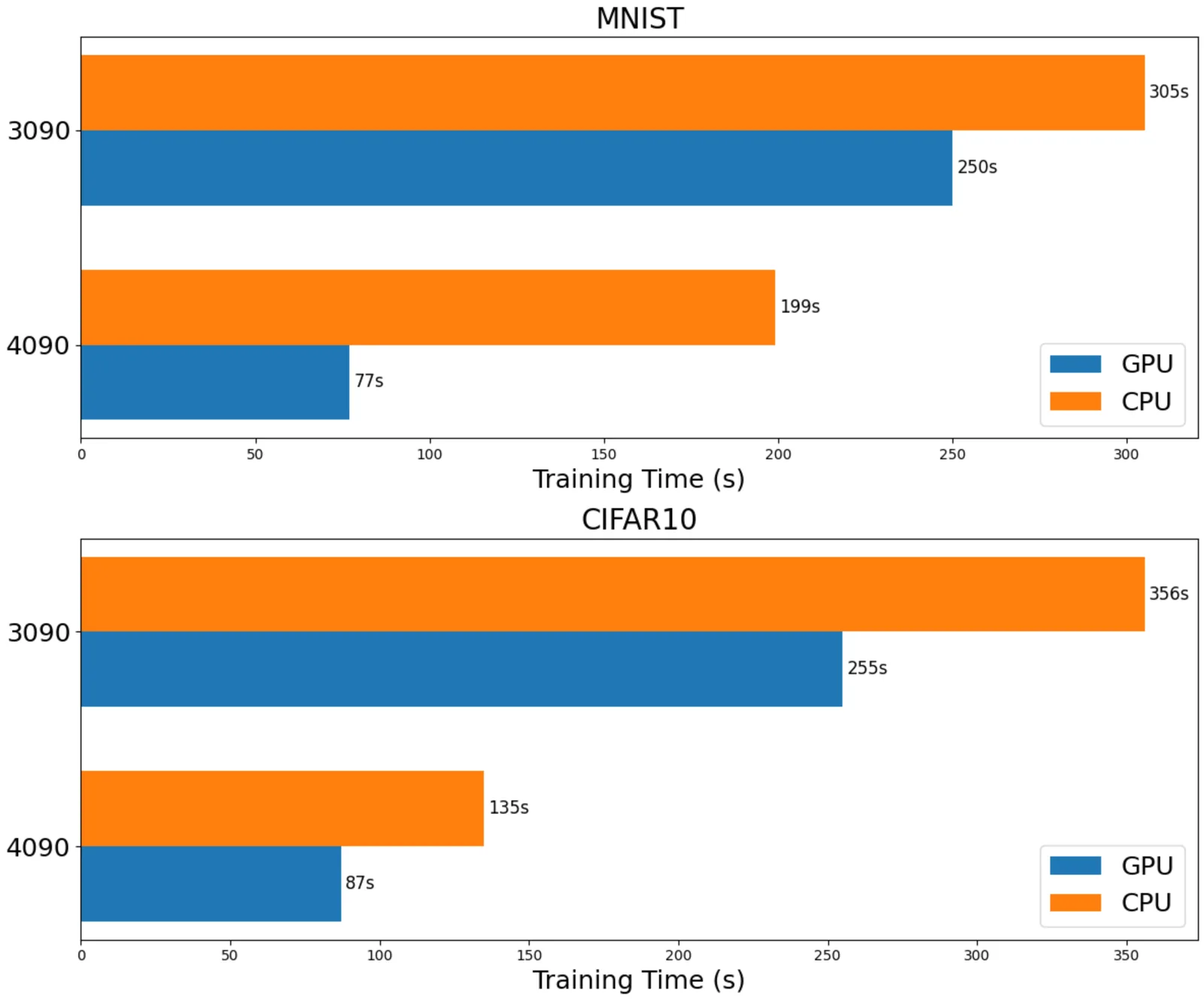
3090 GPUに比べて、4090 GPUでは計算速度が約3倍も早くなっていることが分かります。また、驚くことにCPUで計算してもかなり速く、Core i9(4090 CPU)は3090 GPUよりも早い結果となりました。ただし、今回用いたデータセットおよび学習モデルはかなりサイズが小さいので、CPUとGPUの性能に大きな違いが出なかったと考えられます。いずれにしても、4090 GPUではかなりの性能向上が期待できるので、今後の研究の生産性が向上しそうです。